 说明:
说明:
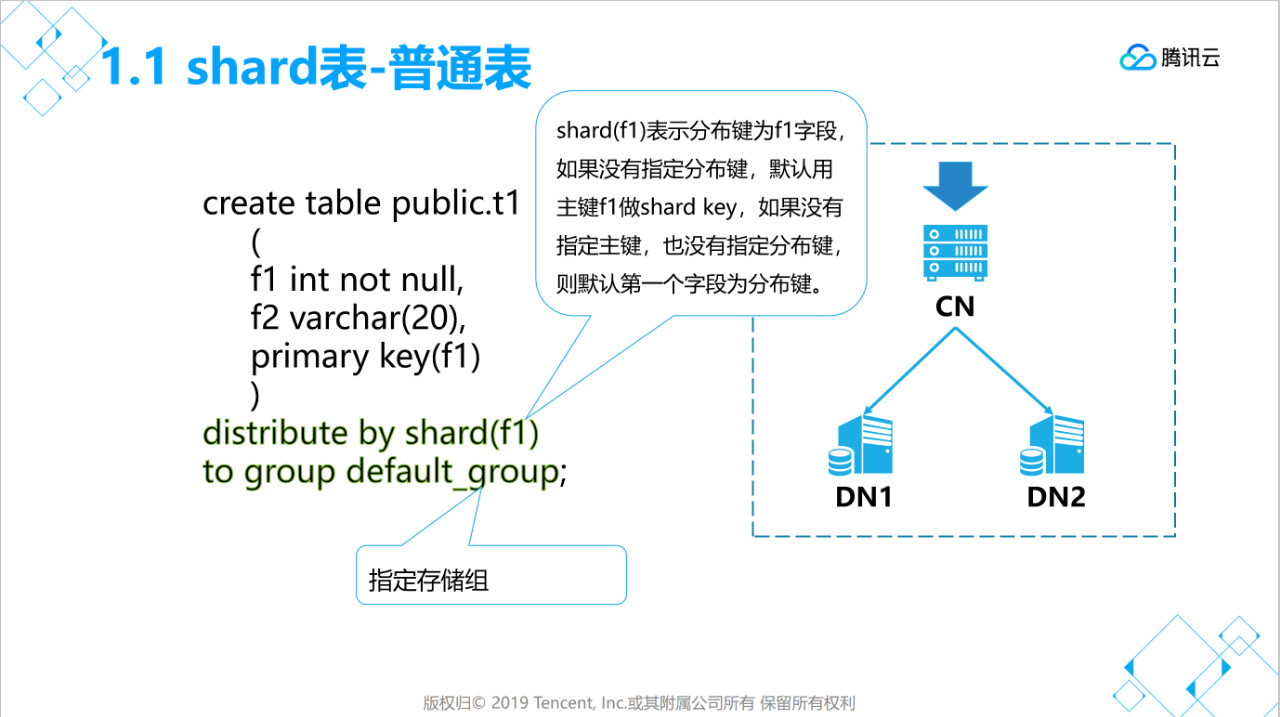
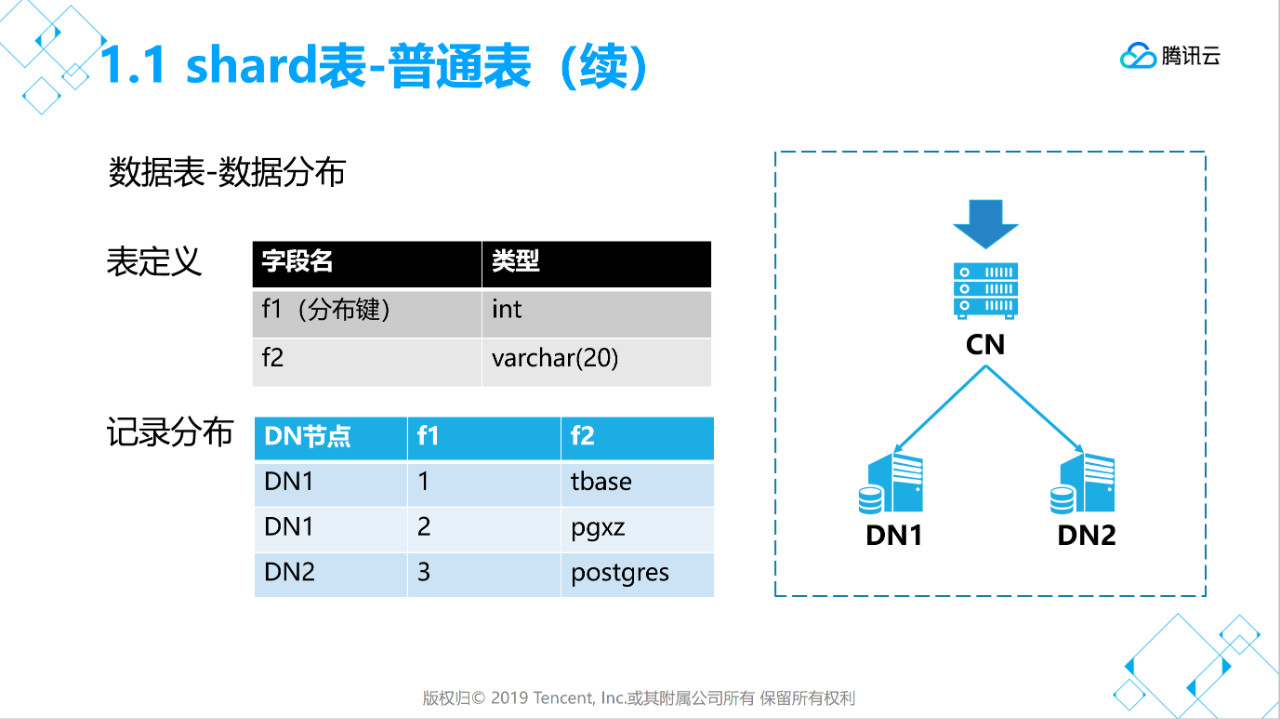
distribute by shard(x) 用于指定分布键,数据分布于那个节点就是根据这个字段值来计算分片。
to group xxx 用于指定存储组(每个存储组可以有多个节点)。
分布键字段值不能修改,字段长度不能修改,字段类型不能修改。
[tbase@VM_0_37_centos shell]$ psql -h 172.16.0.42 -p 11387 -d postgres -U tbasepsql (PostgreSQL 10.0 TBase V2)Type "help" for help.postgres=# create table public.t1_pt(f1 int not null,f2 timestamp not null,f3 varchar(20),primary key(f1)) partition by range (f2) begin (timestamp without time zone '2019-01-01 0:0:0') step (interval '1 month') partitions (3) distribute by shard(f1) to group default_group;CREATE TABLEpostgres=#postgres=# \d+ public.t1_pt Table "public.t1_pt" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+-----------------------------+-----------+----------+---------+----------+--------------+------------- f1 | integer | | not null | | plain | | f2 | timestamp without time zone | | not null | | plain | | f3 | character varying(20) | | | | extended | | Indexes: "t1_pt_pkey" PRIMARY KEY, btree (f1)Distribute By: SHARD(f1)Location Nodes: ALL DATANODESPartition By: RANGE(f2) # Of Partitions: 3 Start With: 2019-01-01 Interval Of Partition: 1 MONTHpostgres=#
说明:
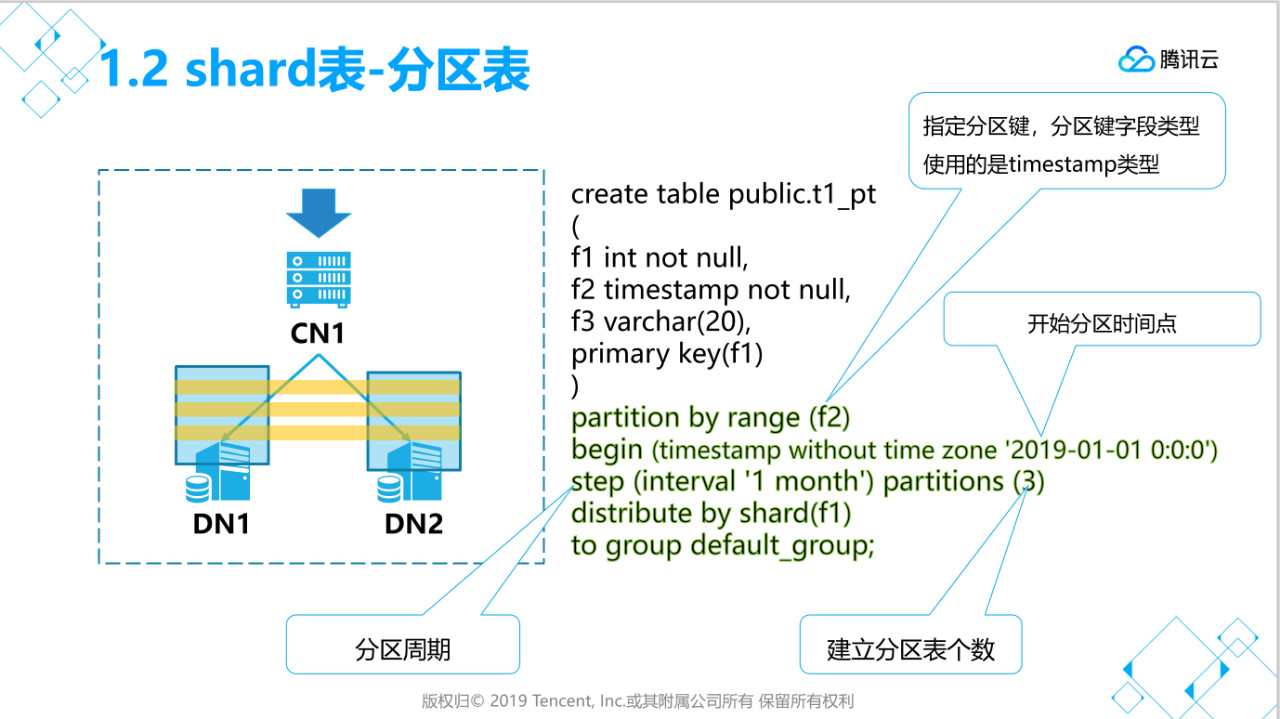
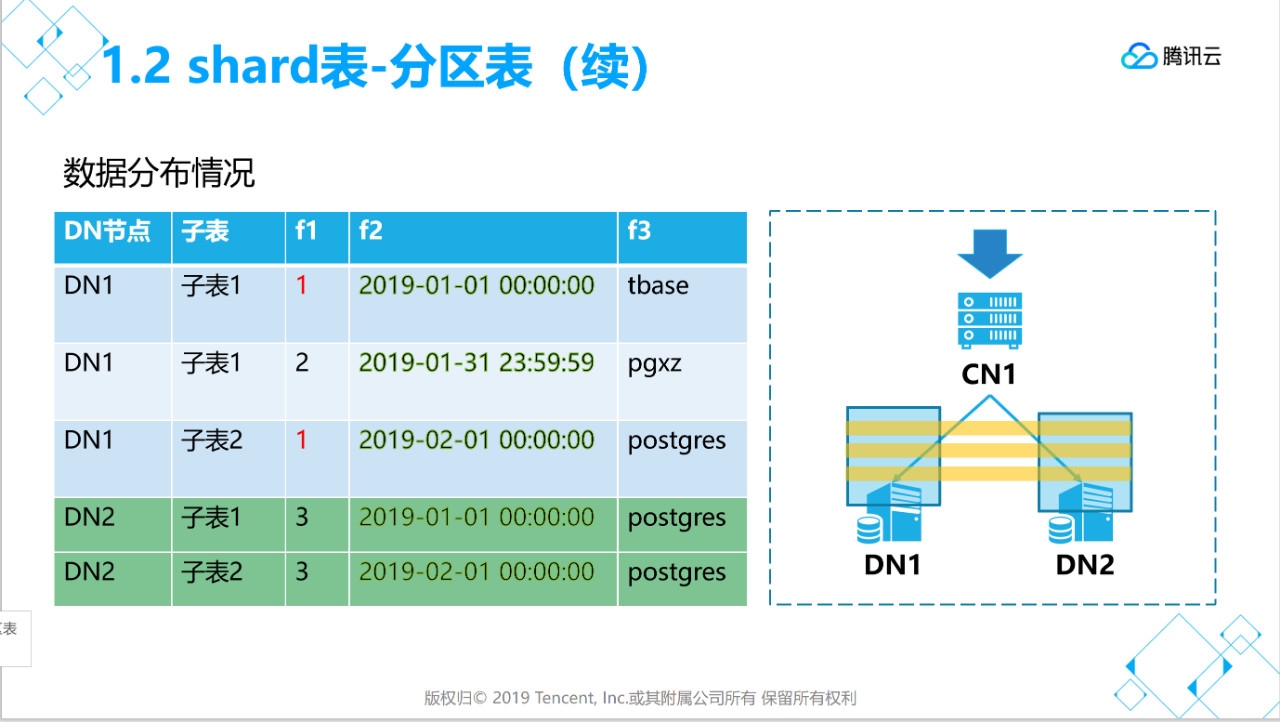
partition by range (x) 用于指定分区键,支持timesamp,int类型,数据分布于那个子表就是根据这个字段值来计算分区。
begin( xxx )指定开始分区的时间点。
step(xxx)指定分区有周期
partions(xx)初始化时建立分区子表个数。
增加分区子表的方法ALTER TABLE public.t1_pt ADD PARTITIONS 2;
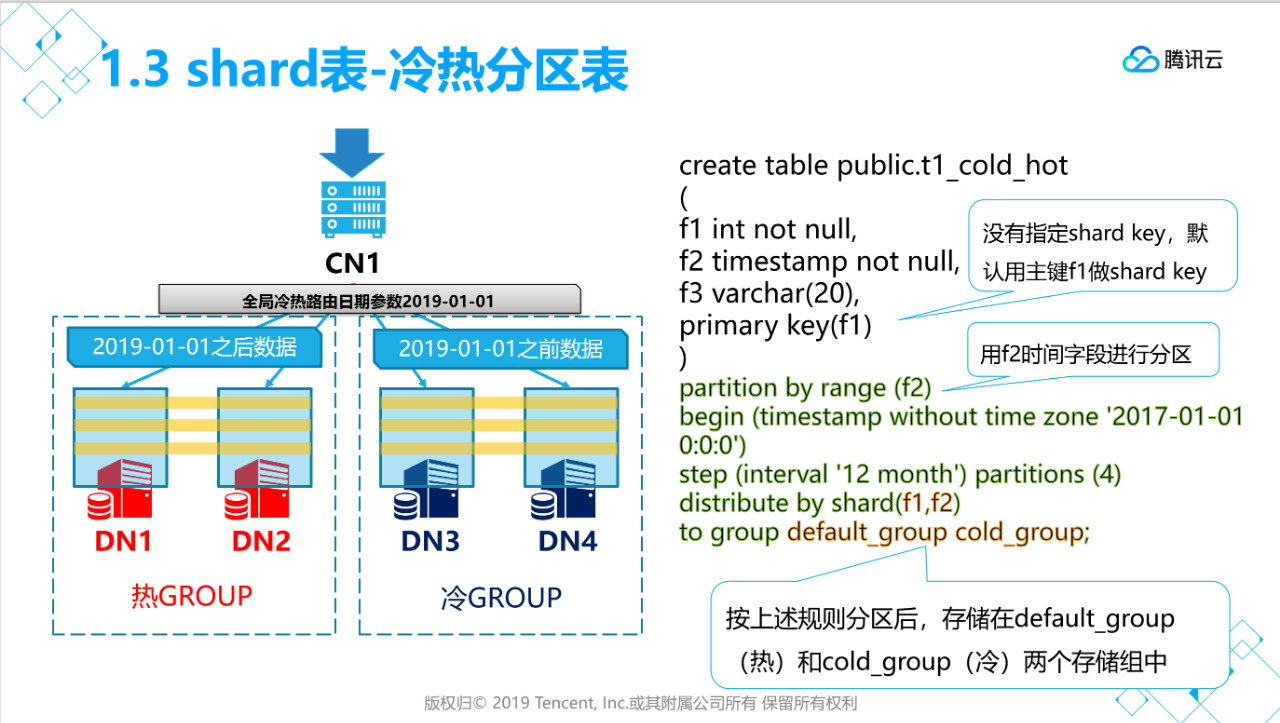
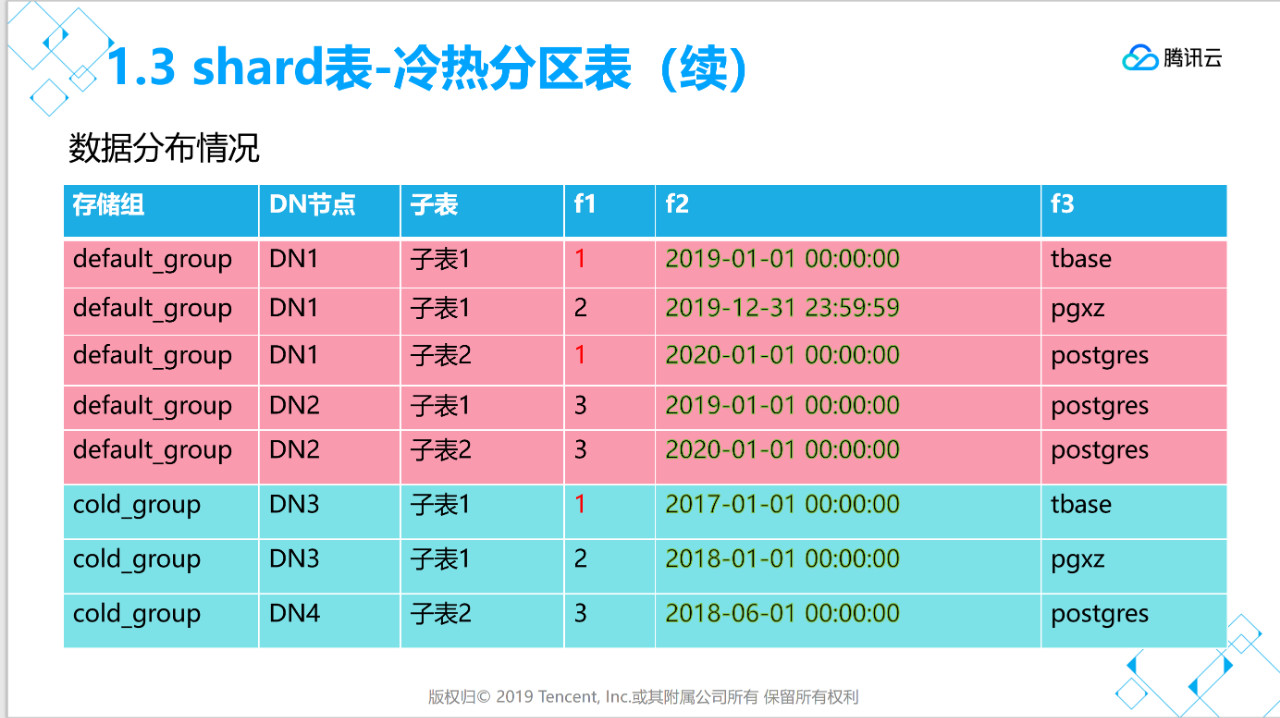
[tbase@VM_0_37_centos shell]$ psql -h 172.16.0.42 -p 11387 -d postgres -U tbasepsql (PostgreSQL 10.0 TBase V2)Type "help" for help.postgres=# create table public.t1_cold_hot(f1 int not null,f2 timestamp not null,f3 varchar(20),primary key(f1)) partition by range (f2) begin (timestamp without time zone '2017-01-01 0:0:0') step (interval '12 month') partitions (4) distribute by shard(f1,f2) to group default_group cold_group;CREATE TABLEpostgres=# \d+ public.t1_cold_hot Table "public.t1_cold_hot" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+-----------------------------+-----------+----------+---------+----------+--------------+------------- f1 | integer | | not null | | plain | | f2 | timestamp without time zone | | not null | | plain | | f3 | character varying(20) | | | | extended | | Indexes: "t1_cold_hot_pkey" PRIMARY KEY, btree (f1)Distribute By SHARD(f1,f2) Hotnodes:dn001 Coldnodes:dn002Partition By: RANGE(f2) # Of Partitions: 4 Start With: 2017-01-01 Interval Of Partition: 12 MONTHpostgres=#
说明:
Distribute By SHARD(f1,f2),冷热分区表需要指定两个字段来做路由,分别是分布键和分区键。
to group default_group cold_group,需要指定两个存储组,第一个是热数据存储组,第二个是冷存储组。
创建时间范围冷热分区表需要有两个group,冷数据的cold_group对应的节点需要标识为冷节点,如下所示
[tbase@VM_0_37_centos shell]$ psql -h 172.16.0.42 -p 11000 -d postgres -U tbasepsql (PostgreSQL 10.0 TBase V2)Type "help" for help .postgres=# select pg_set_node_cold_access(); pg_set_node_cold_access ------------------------- success(1 row)
冷热分区表需要在postgresql.conf中配置冷热分区时间参数和分区级别,如下所示
cold_hot_sepration_mode = 'year' enable_cold_seperation = true manual_hot_date = '2019-01-01'
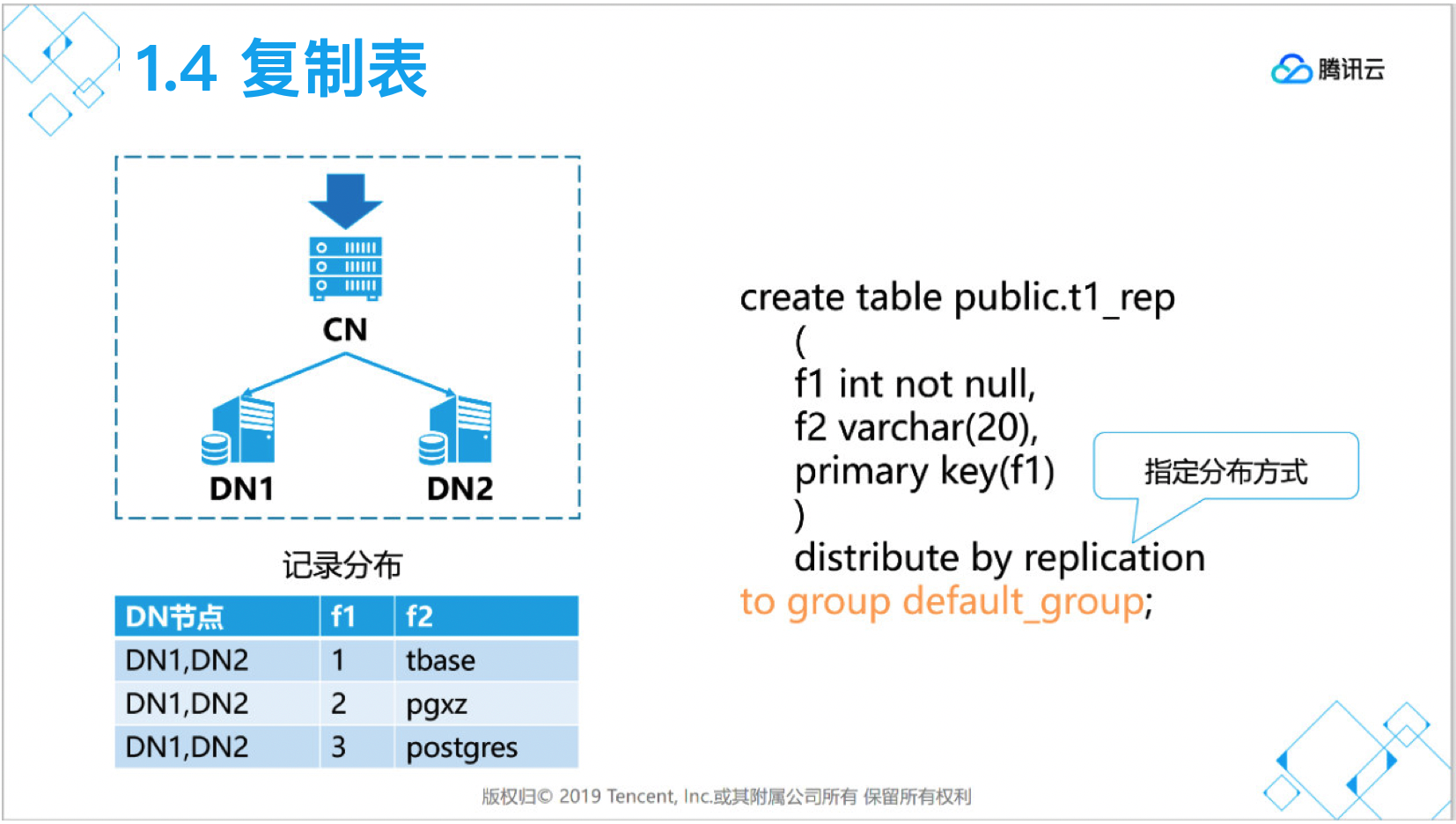
[tbase@VM_0_37_centos shell]$ psql -h 172.16.0.42 -p 11387 -d postgres -U tbasepsql (PostgreSQL 10.0 TBase V2)Type "help" for help.postgres=# create table public.t1_rep(f1 int not null,f2 varchar(20),primary key(f1)) distribute by replication ;to group default_group;CREATE TABLE
说明:
经常要跨库JOIN的小数据量表可以考虑使用复制表。
复制表是所有节点都有全量数据,对于大数据量的数据表不适合。
复制表更新性能较低。
 泡杯长岛冰茶
8799
泡杯长岛冰茶
6025
泡杯长岛冰茶
8799
泡杯长岛冰茶
6025
 AskGuo
4016
AskGuo
4016
 云贝教育
3975
云贝教育
3509
云贝教育
3975
云贝教育
3509
 1菩提行者1
3509
1菩提行者1
3509

 19941464235
19941464235 junle.chen@yunbee.net
junle.chen@yunbee.net




点击加载更多